 Your browser is very old. It's so old that this site will not
work properly as it should.
Your browser is very old. It's so old that this site will not
work properly as it should.
 Find the solution for your needs with our Find My Solutions Tool
Find the solution for your needs with our Find My Solutions ToolElectronically Stored Information Processing
When it comes to Electronically Stored Information Processing,
TIMG adheres to strict policies and methodologies when preparing data for our clients. We deploy the same continuous process driven workflows, regardless of the size of each tranche. This ensures that the processes are completed correctly, and that all material is accounted for in a defensible way. This process follows the highest standards as well as full respect for the industry guidelines.

EDISCOVERY
Electronically Stored Information Processing
TIMG adheres to strict policies and methodologies when preparing data for our clients. We deploy the same continuous process driven workflows, regardless of the size of each tranche. This ensures that the processes are completed correctly, and that all material is accounted for in a defensible way. This process follows the highest standards as well as full respect for the industry guidelines.
| Our ESI Processing includes data extraction, de-duplication, rendering files to PDF or native file format, document stamping and full OCR of material.
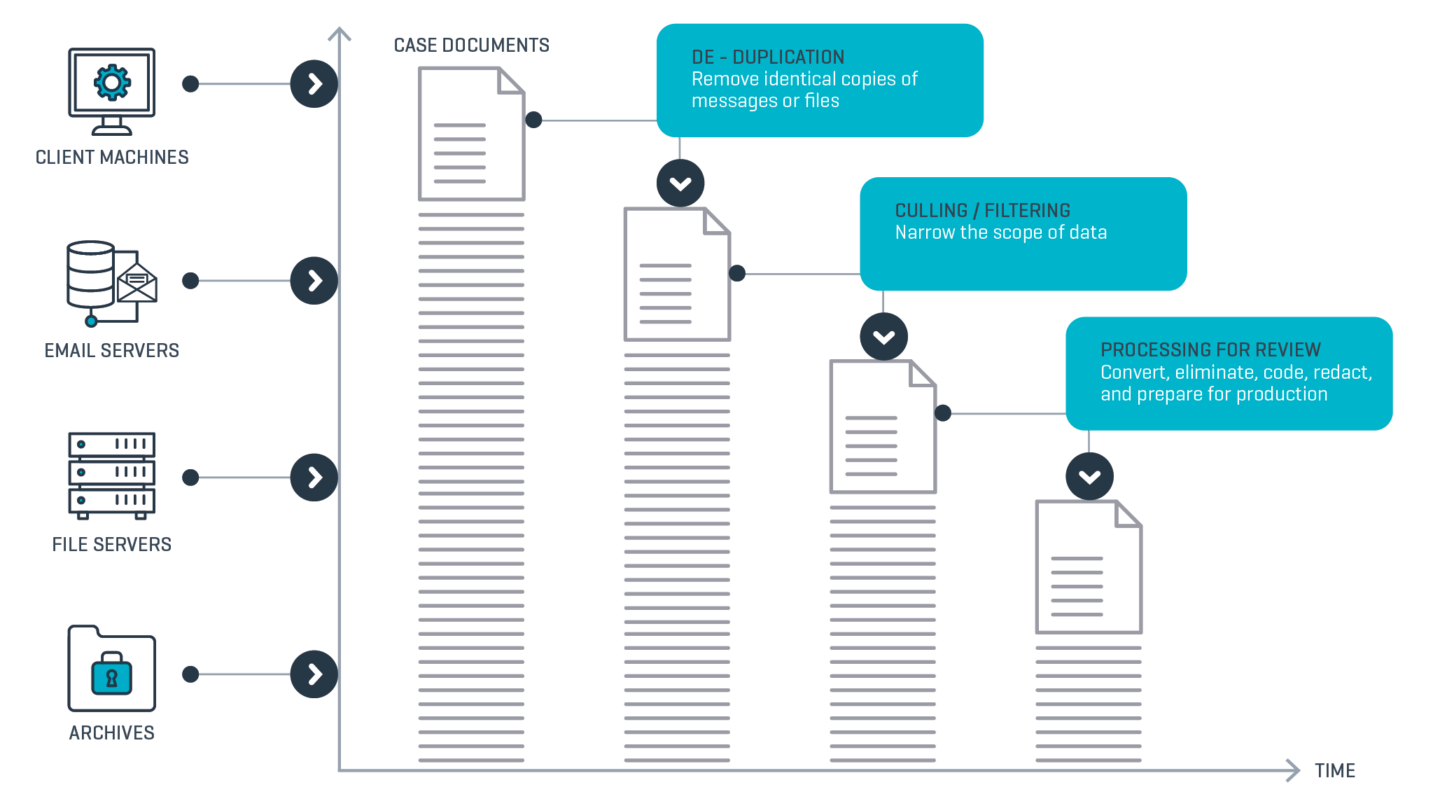
In addition to the document delimiting, numbering, and extraction of standard metadata fields,
TIMG will also provide the following complete steps when processing data:
- DeNISTing – The goal of the TIMG ESI processing team is to reduce the size of a document set in a defensible manner. This means that for a typical processing project, they need to utilise proven technologies and industry standards to filter the dataset in order to eliminate non-user generated data (such as operating systems that cannot be reviewed) from the useable documents that are required for review.
- De-duplication – De-duplication is the process of eliminating files with the same content from the dataset. Duplicate documents can be removed from either the entire case or from a particular custodian.
- Email Threading – Identifies the most inclusive email in a chain as the master document, and the rest as duplicates. This allows the user to review a complete conversation in one document.
- Exception handling – Occurs in at least two stages throughout the processing timeline:
1. Pre-processing – Documents will be identified as soon as they are loaded into the processing platform as being an “issue” document.
2. Post-processing – Documents will be identified with reasons why they were unable to be processed, such as but not limited to encrypted files, files that are password protected, system files, or files that are corrupt.
- Data Culling – A data set can also be further narrowed by applying search terms, phrases, concepts, date ranges, data locations, and other client-specified factors.
o Key word (basic, first-round with no testing. Subsequent runs at hourly rate);
o Date range;
o Custodian; and
o File type. - Optical Character Recognition (OCR) – Applying OCR ensures that images and scanned documents are text-searchable. TIMG’s industry-leading processing tools can automatically identify documents that are not text-searchable, and can apply OCR in multiple languages.
- Rendering – Where possible, TIMG will render all electronic files to searchable multi-page PDF files. Electronic files that are not easily rendered (such as spreadsheets, videos, and CAD files), will remain in their native file format. Any files that cannot be rendered will also utilise a document Placeholder page, instructing the reviewer to view the native file as it was unable to be rendered.
- Validation – To easily upload data to a review platform, a load file is created. TIMG processing standards ensure that a valid load file is generated at the end of each task. Our standard validation checks ensure both documents and metadata are complete, and are in a format compatible with the review platform.
- Process Reporting – Includes a high level snapshot of file counts, file types, de-duplication counts, custodian and source counts, and exception reporting counts.
- Data Analytics – Part of the TIMG Processing output includes indexing and enrichment of the completed data set as it is imported into the review case. This allows users to draw together ‘like documents’, based on similarity of concepts and content. This coupled with powerful visualisations can increase both the speed and accuracy of coding decisions whilst reducing costs.
- Seamless import to Nuix Discover – Drawing on the interoperability within the Nuix ecosystem, TIMG’s processing team can ensure an error-free, seamless , and complete import into leading eDiscovery review platform Nuix Discover.
Access our eDiscovery solutions today
Call 1300 986 856 to speak to a consultant
Melbourne, Brisbane, Darwin, Adelaide, Hobart and Perth